UE4:ShadecodeLibrary拆分
前言
UE4的项目设置的Packaging中提供了Share Material Shader Code,开启选项后会把ShaderCode从每一个材质中拿出单独的放在一个.ushaderbytecode文件中,目的是减少包体大小,该文件会在游戏启动时加载。
如果是用UE4的Pak分包机制,那么打包过程会处理掉每个Pak中需要的Shader,不用自己去关心ShaderArchive的生成。如果是更新包的话,也有对应的方法去生成ShadeArchive文件的Patch。
由于目前的情况是并没有使用UE4的分包机制,这造成虽然启用了Share Material Shader Code,但是由于UE4的材质机制,单个材质会编译出多个Shader,每次只要涉及到Material改动都会让整个.ushaderbytecode文件变掉,再加上安卓端的Vulkan格式的ShaderArchive比较庞大,每次更新都需要将Global和Project两个ShaderArchive文件进行更新,很浪费资源,所以希望找到将ShaderArchive拆开。
期望的结果是,将Project的.ushaderbytecode文件分成几个,且不会同时需要更新,大小趋近。这样在美术更新了材质的时候,更新量不会很大。
如果是用UE的Pak机制,那么是完全不需要用到的
注意
4.26中ShaderLibrary与4.27之后的差异较大,不过不同点是类的设计,具体方法是一致的,下文是在4.26的版本中完成的。
ShaderArchive生成过程
首先看一下ShaderArchive文件是如何生成的
通过log查询源码,发现UCookOnTheFlyServer::SaveShaderLibrary方法
FShaderCodeLibrary结构体,是在cook阶段生成的Unique ShaderCode的集合,最后会保存为后缀.ushaderbytecode的文件。
在4.26中,在FShaderCodeLibraryImpl中,有一个数组EditorShaderCodeArchive,数组中的数据类型是FEditorShaderCodeArchive,FShaderCodeLibrary通过方法调用FShaderCodeLibrary::SaveShaderCode最后生成了ShaderArchive文件:


大致看一下该函数都做了什么
1 | |
可以得知.ushaderbytecode文件其实是FShaderCodeLibrary中的数组EditorShaderCodeArchive中保存的数据类型FEditorShaderCodeArchive生成的。
拆分方法
那么再去看一下FEditorShaderCodeArchive这个结构体
首先发现一些看名字就知道干什么的,已经很可能已经满足我们拆分文件的需求的成员函数:
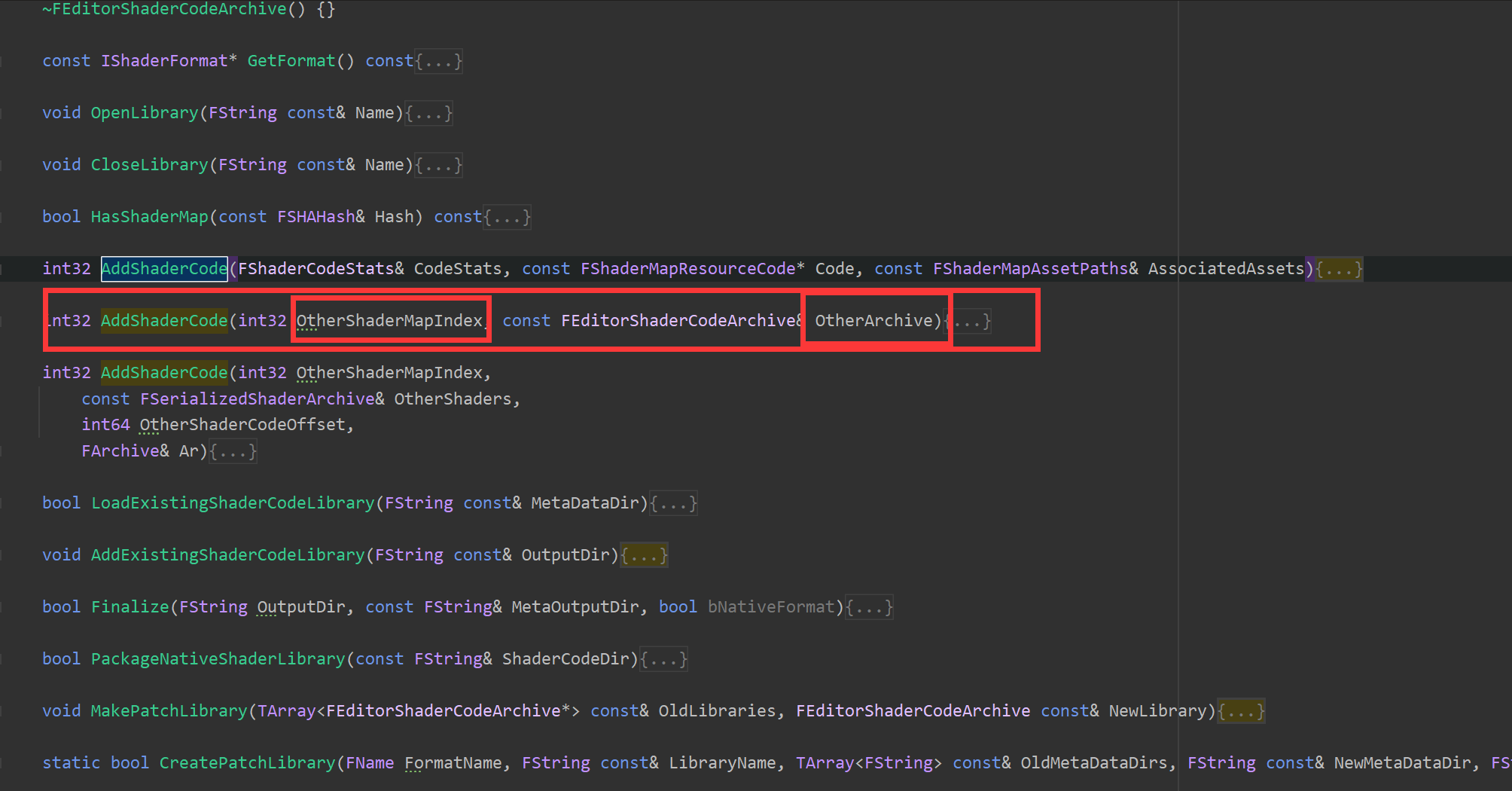
圈起来的函数的参数都直接写了 一个是int型的OtherShaderMapIndex,一个是OtherArchive,看起来就是从另一个Archive中通过一个index来给自己添加ShaderCode,看一下这个函数的实现:
1 | |
发现果然是这样的,相当于我们可以创建一个新的FEditorShaderCodeArchive,命名为NewShaderArchive1,此时他是一个完全的空的对象。
再创建一个空的FEditorShaderCodeArchive,名字叫OldShaderArchive,我们把Cook生成的Project的通过Open方法读取进来。
我们的目的是把OldShaderArchive拆分成若干个新的,那么可以再继续创建需要的FEditorShaderCodeArchive。
现在我们已经有了Cook生成的.ushaderbytecode文件,也就是AddShaderCode方法的第二个参数,也有了要调用这个方法的NewShaderArchive1,那么第一个参数OtherShaderMapIndex是什么?
看一下在函数中这个int32是干什么的
OtherArchive.SerializedShaders.ShaderMapHashes[OtherShaderMapIndex]
OtherArchive是FEditorShaderCodeArchive
SerializedShaders是:
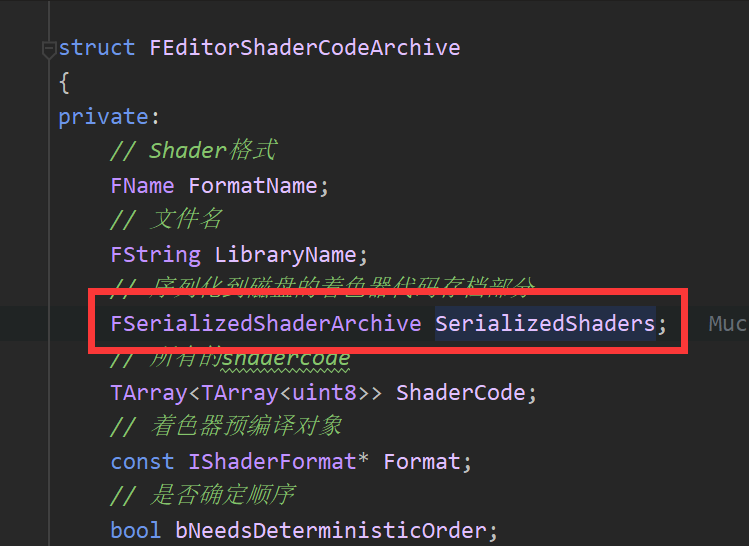
那么ShaderMapHashes是:
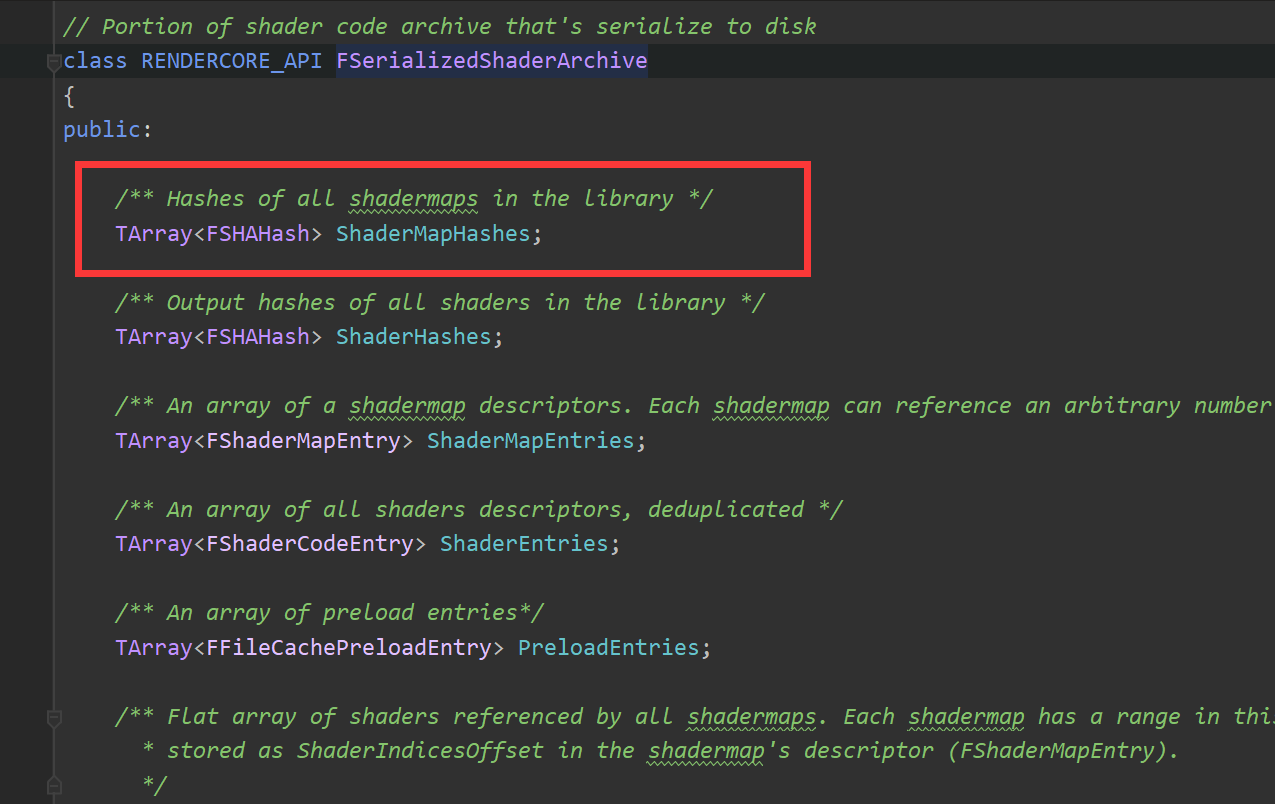
是这个数组的索引
那么最简单的拆分思路就是,假设这个数组一共有100个元素,那么可以每10个就创建一个新的FEditorShaderCodeArchive进行AddShaderCode操作,满十个就保存,就可以把一个巨大的ShaderArchive文件拆开了。
但这并不能满足我们的根本目的,我们的最终目的是减少更新量,希望美术在修改了一些材质实例的时候,尽可能影响到少数的ShaderArchive
那么就需要知道Material和MaterialInstance和FSerializedShaderArchive的关系了。
再看一下FSerializedShaderArchive这个结构体的内容
该结构体的注释写的是,序列化到磁盘的着色器代码存档部分(无情机翻)
成员变量ShaderMapHashes是一个FSHAHash的数组,注释为,所有shadermaps的Hash
下一个成员变量ShaderHashes也是一个FSHAHash数组,但是和ShaderMapHashes区别是,这是一个所有的shader的Hash的数组
那么shadermap是一个什么,在ShaderMapEntries的注释中看到,每一个shadermap可以引用(查询?)到任意数量的shader
这个引用关系是通过FShaderMapEntry建立的,暂不深究。
通过对ShaderMapHashes的所有引用发现,在UE的Pak机制下生成Patch的时候有这么一个方法:
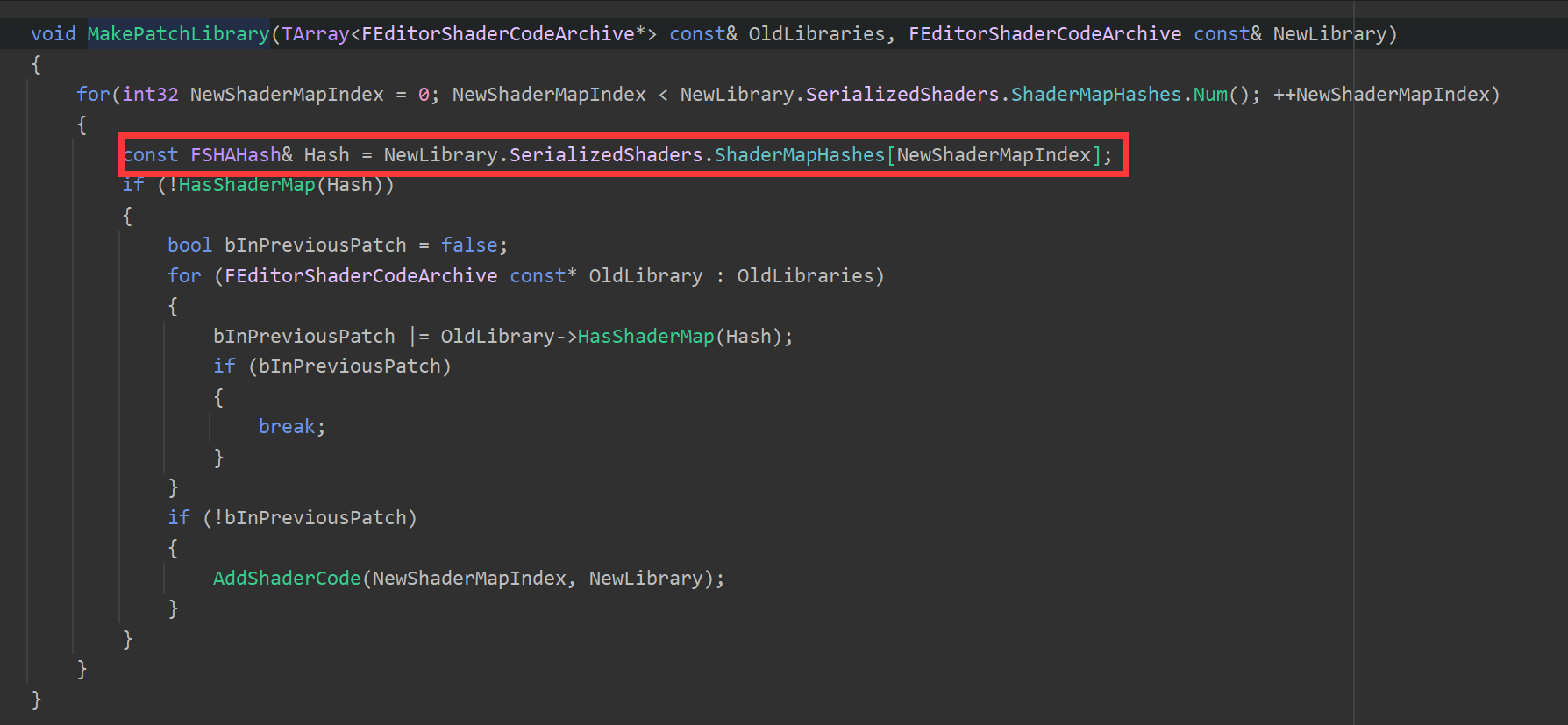
可以看出,UE在生成ShaderArchive的Patch的时候,是将一个新的ShaderArchive文件和若干个旧的进行对比,对比的内容就是ShaderMapHash,差异部分通过AddShadercode
添加到新的ShaderArchive中。
其中 FEditorShaderCodeArchive的Finalize方法是ShaderArchive文件的二进制保存方法,在添加完毕Sahdercode之后可以调用该方法进行保存。
到了这里,已经有了将ShaderArchive拆开的基本方法,接下来需要考虑的是拆分的规则。
拆分思路
众所周知,Cook阶段生成ShaderArchive的同时还会生成ShaderAssetInfo文件:

该文件内是ShaderMapHash和起映射到的Assets,如图:
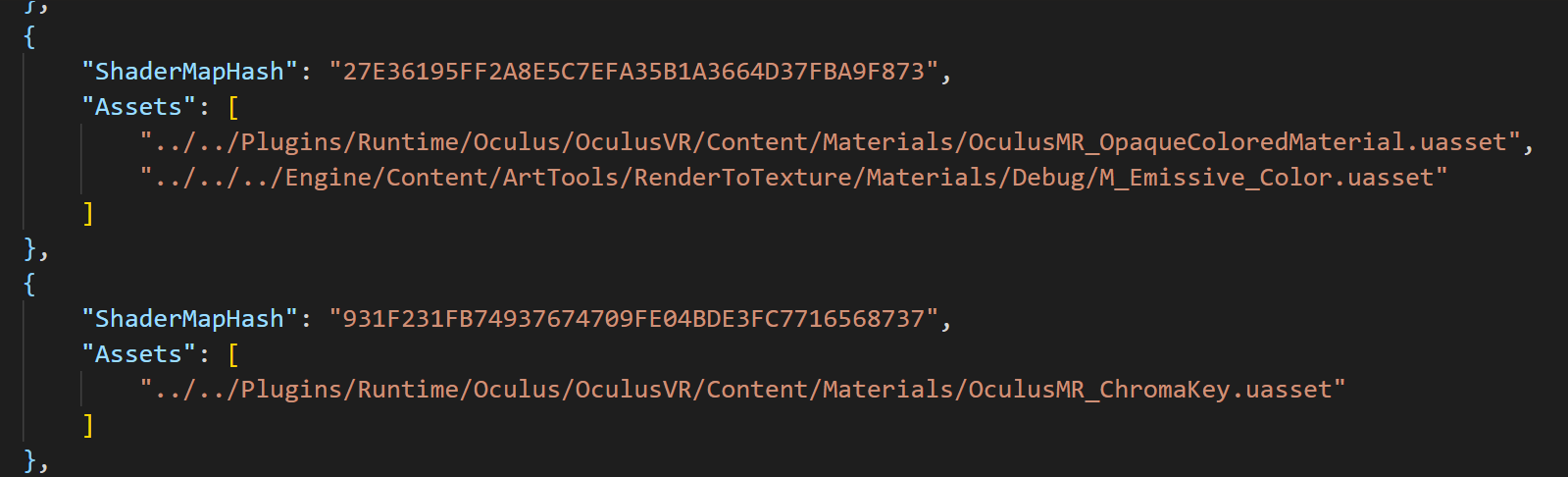
通过Json文件可以获取到ShaderMapHash到Material(以及MaterialInstance)的映射,将映射反过来就是Asset到ShaderMapHash的关系。
通过ShaderMapHash可以获取到在ShaderArchive中对应的Index
对以上进行处理就得到了Asset——ShaderMapHash——Index
在项目中我们的材质和材质实例一般是这样的:
- Material_A
- MaterialInstance_A_01
- MaterialInstance_A_02
- MTI_A_02_01
- Material_B
- MaterialInstance_B_01
当一个Material被修改后,UE会去寻找被Material使用的.ush/.usf文件,把这些Material Graph转换成HLSL代码,开始编译shader,相关的MaterialInstance都会变动。
如果我们把上表中的Material_A和它的子类们放在一个ShaderArchive_A里,把Material_B放到ShaderArchive_B里,那么当A材质修改的时候,ShaderArchive_B是不会受到影响的。
这样看来,只需要获取材质和材质实例的父子关系,将同一个Material相关的所有Asset的ShaderHashMap都Add到同一个ShaderArchive中,就可以在美术更新的时候只影响到对应的ShaderArchive
只需要建立两张表:
Material——MaterialInstance
Asset——ShaderMapHash——Index
那么在分开Material的时候,就要根据具体项目的情况来考虑了,这个和美术资源的存放规则有关系,可以根据频繁修改的情况按照某一路径下来拆分,也可以考虑将某一个拥有大量子类的Material单独拆分,如果一个Material有大量的Material实例,最后编译出的shader体积是很大的,完全可以单独拆分出一个ShaderArchive
最后,在游戏启动的时候将所有的ShaderArchive进行加载,游戏就可以正常使用Shared Shader Code